问题一:Prometheus 内存持续上升,最终OOM
版本:v2.22.2
变更事项:Prometheus磁盘升级 1.6T → 6.5T、保留时间 20d → 90d
保留时间会影响另一项参数:storage.tsdb.max-block-duration,当这个参数不显示配置时,默认等于保留时间的10%,也就是说其值从2d → 9d
直接导致Prometheus需要另外启动协程,将2d的block进一步合并为更大的block,需要消耗更多的CPU,有可能规定时间内无法执行完,指标量还一直在加,导致后续的任务也无法完成
副本1 走变更,副本 0 回退,观测Compaction次数对比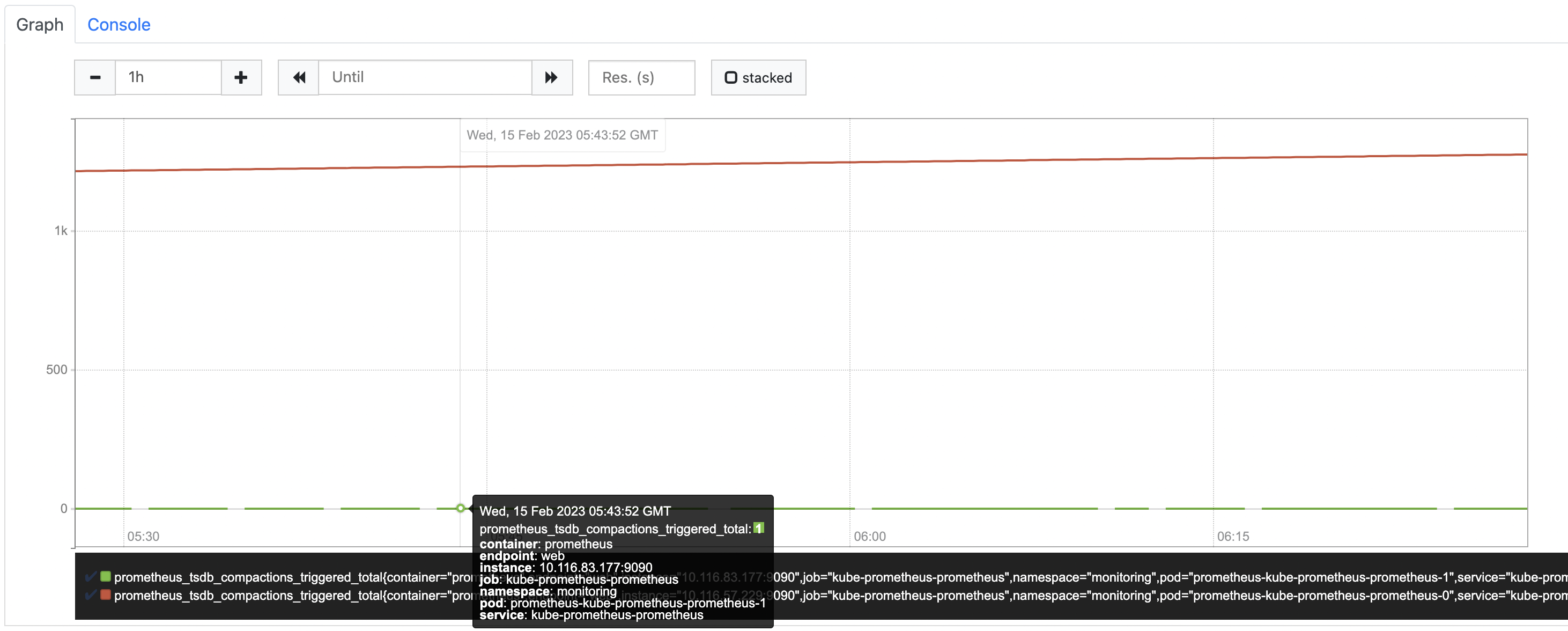
结论:
- 副本0的Compaction次数符合预期
- 副本1的Compaction次数停在了1,说明Compaction的任务一直没有完结
关键日志:
如下图block时间范围:[2023-01-21 02:00:00, 2023-01-22 14:00:00],间隔1.5d,压缩花费52m
level=info ts=2023-02-15T04:57:02.036Z caller=compact.go:440 component=tsdb msg="compact blocks" count=2 mint=1674237600000 maxt=1674367200000 ulid=01GS9KXZ9ZH7QBKJ0YGMWCKQVP sources="[01GQAFN2DXA7TYZ4BW91YWX9S0 01GQCDH4A1EDNV69RKBVHSPS5G]" duration=52m19.604933448sCompact 是取3个同样大小的block进行合并,所以下一个更大的block的时间区间将达到6d18h,花费时间可能会突破3h,那对整体的任务肯定会造成影响
临时解决方案:
- 配置 storage.tsdb.max-block-duration = 2d,锁定住最大的block时间范围
接下来排查为什么任务无法完结,CPU耗费在了哪里?
通过pprof,看 Compact 协程的运行情况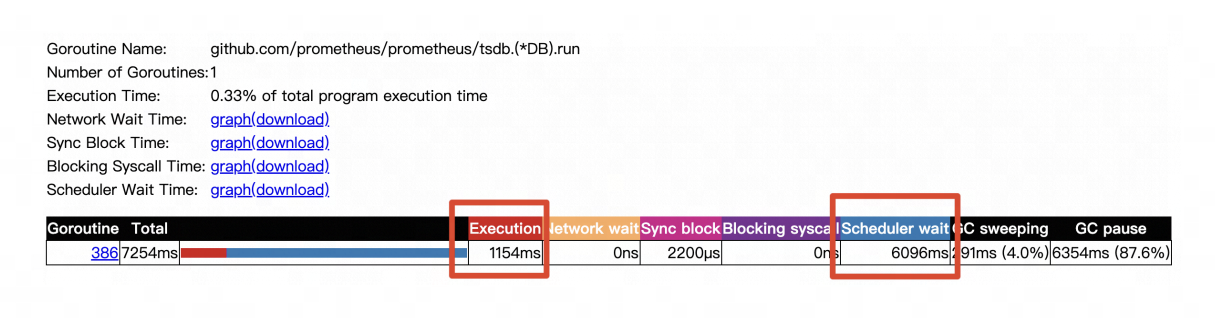
分析:运行了1s,但等待调度的时间达到了6s,抢不到CPU!接下来分析CPU被什么模块占用了
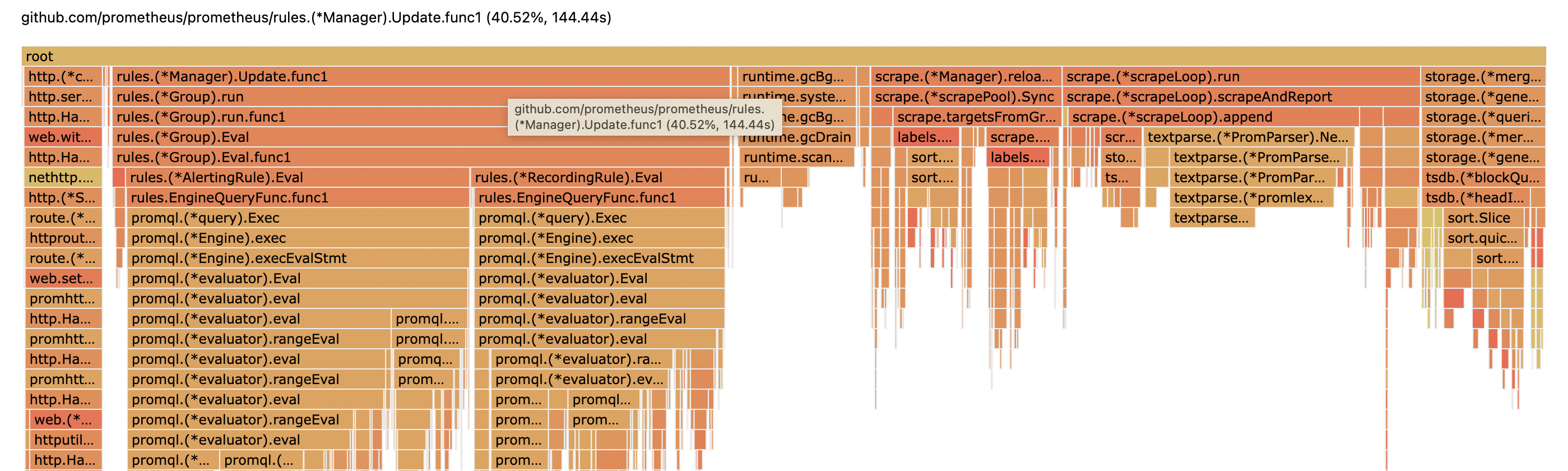
有一块 scrape.reload 的CPU占比较高,这块和服务发现有关系,查看代码得知,我们用的Prometheus版本,会固定每 5s 做一次targets列表的刷新
社区对该参数做了可配置的修改:https://github.com/prometheus/prometheus/commit/41630b8e8835585098f345b0d9740d7107ffb6eb
在 v2.36.0 版本里发布上线。discovery-reload-interval flag修改为2m后,CPU使用大大降低,放开 max-block-duration 到 9d,Compaction的任务也能正常完成了
继续深究下,为什么reload target这么耗费cpu呢?
target对象里会包含目标的一些元数据,包括namespace、labels、annotations等,这些会参与排序、唯一性判断等操作,很消耗cpu
看下我们下发的一个Pod:
metadata:
name: xxx
generateName: xxx
namespace: xxx
annotations:
cloudnative.com/http-probe.sh: |
http_probe(){
local FUNC="$1" URL="$2" RETRY="$3" SLEEP="$4" \
TIMEOUT="$5" SLEEP_WHEN_SUCCEED="$6" BASEDIR="$7" \
PROBE_RESULT_DIR="${PROBE_RESULT_DIR:-".probe-result"}"
local RESP_BODY_FILE="$BASEDIR/$PROBE_RESULT_DIR/$FUNC.res" ERROR_FILE="$BASEDIR/$PROBE_RESULT_DIR/$FUNC.err" && \
{ [[ ! -d "$BASEDIR/$PROBE_RESULT_DIR" ]] && mkdir -p "$BASEDIR/$PROBE_RESULT_DIR"; }
local CHECK_STATUS BODY ERROR
for ((i=1;i<="$RETRY";i++)); do
rm -f "$RESP_BODY_FILE" "$ERROR_FILE"
CHECK_STATUS="$(curl -ksSL -w '%{http_code}' -m "$TIMEOUT" "$URL" -o "$RESP_BODY_FILE" 2>"$ERROR_FILE")"
[[ "$CHECK_STATUS" == 20* ]] && echo "$FUNC ok!" && {
if [[ ! -z "$SLEEP_WHEN_SUCCEED" ]]; then
echo "sleep "$SLEEP_WHEN_SUCCEED"s before "$FUNC" return ..." && sleep "$SLEEP_WHEN_SUCCEED"
fi
return 0
}
(("$i"<"$RETRY")) && sleep "$SLEEP"
done
echo "$FUNC failed after $RETRY times retry ..."
[[ -f "$RESP_BODY_FILE" ]] && {
BODY="$(cat "$RESP_BODY_FILE" | uniq)"; [[ ! -z "$BODY" ]] && echo "http code is: $CHECK_STATUS; response body is: $BODY"
}
[[ -f "$ERROR_FILE" ]] && {
ERROR="$(cat "$ERROR_FILE" | uniq)"; [[ ! -z "$ERROR" ]] && echo "error is: $ERROR"
}
return 1
}
cloudnative.com/offline-once.sh: |
. "$(cd "$(dirname "$0")";pwd)/http-probe.sh"
offline(){
local URL="http://localhost:8888/health/offline"
local RETRY=1
local SLEEP=10
local TIMEOUT=3
local APPHOME=/home/appops
local SlEEP_SECONDS_WHEN_SUCCEED=0
http_probe "offline(下线)" "$URL" "$RETRY" "$SLEEP" "$TIMEOUT" "$SlEEP_SECONDS_WHEN_SUCCEED" "$APPHOME"
} && offline
cloudnative.com/offline.sh: |
. "$(cd "$(dirname "$0")";pwd)/http-probe.sh"
offline(){
local URL="http://localhost:8888/health/offline"
local RETRY=2
local SLEEP=10
local TIMEOUT=5
local APPHOME=/home/appops
local SlEEP_SECONDS_WHEN_SUCCEED=10
http_probe "offline(下线)" "$URL" "$RETRY" "$SLEEP" "$TIMEOUT" "$SlEEP_SECONDS_WHEN_SUCCEED" "$APPHOME"
} && offline
cloudnative.com/online-once.sh: |
. "$(cd "$(dirname "$0")";pwd)/http-probe.sh"
online(){
local URL="http://localhost:8888/health/active"
local RETRY=1
local SLEEP=10
local TIMEOUT=3
local APPHOME=/home/appops
local SlEEP_SECONDS_WHEN_SUCCEED=0
http_probe "online(上线)" "$URL" "$RETRY" "$SLEEP" "$TIMEOUT" "$SlEEP_SECONDS_WHEN_SUCCEED" "$APPHOME"
} && online
cloudnative.com/online.sh: |
. "$(cd "$(dirname "$0")";pwd)/http-probe.sh"
online(){
local URL="http://localhost:8888/health/active"
local RETRY=50
local SLEEP=10
local TIMEOUT=30
local APPHOME=/home/appops
local SlEEP_SECONDS_WHEN_SUCCEED=0
http_probe "online(上线)" "$URL" "$RETRY" "$SLEEP" "$TIMEOUT" "$SlEEP_SECONDS_WHEN_SUCCEED" "$APPHOME"
}
check(){
local URL="http://localhost:8888/api/test"
local RETRY=50
local SLEEP=10
local TIMEOUT=30
local APPHOME=/home/appops
local SlEEP_SECONDS_WHEN_SUCCEED=0
http_probe "check(存活状态)" "$URL" "$RETRY" "$SLEEP" "$TIMEOUT" "$SlEEP_SECONDS_WHEN_SUCCEED" "$APPHOME"
}
check && online
cloudnative.com/startup.sh: >
HTTP_CODE="$(curl -ksSL -w '%{http_code}' -m 3 -o /dev/null
"http://localhost:8888/api/test")"
(("$HTTP_CODE"<200)) || (("$HTTP_CODE">=400)) && exit 1
exit 0
cloudnative.com/status.sh: >
HTTP_CODE="$(curl -ksSL -w '%{http_code}' -m 3 -o /dev/null
"http://localhost:8888/api/test")"
(("$HTTP_CODE"<200)) || (("$HTTP_CODE">=400)) && exit 1
is_json(){
local INPUT="$1"
[[ ! -z "$(jq -c "objects"<<<"$INPUT" 2>/dev/null)" ]] && return 0 || return 1
}
IFS='#' read -r RESPONSE_BODY HTTP_CODE < <(curl -m 3 -s -w
'#%{http_code}' 'http://localhost:8888/health/status')
(("$HTTP_CODE"<200)) || (("$HTTP_CODE">=400)) && exit 1
[[ -z "$RESPONSE_BODY" ]] && exit 0
RESPONSE_BODY="${RESPONSE_BODY,,}"
if [[ "$RESPONSE_BODY" != "200" ]] && [[ "$RESPONSE_BODY" != "alive" ]] &&
[[ "$RESPONSE_BODY" != "ok" ]] && [[ "$RESPONSE_BODY" != "online" ]]; then
if ! is_json "$RESPONSE_BODY"; then
exit 1
fi
CODE="$(jq -r '.code'<<<"$RESPONSE_BODY")"
[[ "$CODE" == "200" ]] || exit 1
fi可以看到,annotations里有很多的脚本,内容非常多,直接导致reload时要做的计算量非常的大
解决方式:
官方社区没有对此有任何的配置。只能内部魔改,将annotation从target的元数据里去掉,核心修改如下:
- https://github.com/ryanwuer/prometheus/commit/8d345798884a2cab445766b9f5884f0c870deec6 —— 去掉 Pod 的 Annotation 和 label-present
- https://github.com/ryanwuer/prometheus/commit/660e9419b354c2cdeddfa6ddc2253a42f44e467a —— 去掉 Endpoint 自己的元数据信息
考虑到我们内部都是通过
- ServiceMonitor —— 通过 Service 的 Label
- PodMonitor —— 通过 Pod 的 Label
做服务发现,上述改动不会影响服务发现,实测CPU和内存使用下降非常明显,算是一个比较好的解决方案
问题二:联邦模式下,子Prometheus双副本部署,通过thanos-query暴露服务,中心Prometheus如何配置拉取地址
方式1:
thanos-query 不提供 /federate 接口,需要做一层转化,如下项目可满足需求:
https://github.com/snapp-incubator/thanos-federate-proxy
方式2:
- 子Prometheus配置自己的负载均衡域名,流量随机转到一台实例
- 中心prometheus,配置target为负载均衡域名,并丢弃 prometheus 副本标签,让指标看起来来自同一个实例
metric_relabel_configs:
- regex: prometheus_replica
action: labeldrop注意,该种方式可能出现如下日志报错:
Error on ingesting out-of-order samples 可以应用会话保持策略,如通过ingress-nginx暴露服务,可在Ingress里添加如下注解:
nginx.ingress.kubernetes.io/affinity: cookie
nginx.ingress.kubernetes.io/session-cookie-expires: "172800"
nginx.ingress.kubernetes.io/session-cookie-max-age: "172800"
nginx.ingress.kubernetes.io/session-cookie-name: route但上述策略,依赖于Cookie,适用于浏览器环境,不适用于Prometheus的联邦拉取。但实际观察来看,上述报错不会影响数据的准确性,Prometheus会自动丢弃掉这些数据
方式3:
- 配置拉取两个副本的Prometheus的数据(注意服务暴露方式,Statefulset 部署模式下,基于Headless的Service)
- 查询侧去重,应用
max_over_time、sum without(replica)等
问题三:Prometheus Pod 反复重新调度,Pod一直处于销毁和重建中
我们通过 Prometheus-operator 交付 Prometheus Stack,operator会读取所有的PrometheusRule,并合并写到configmap中,并挂载给对应的 Prometheus Pod
- configMap:
defaultMode: 420
name: prometheus-kube-prometheus-kube-prome-prometheus-rulefiles-0在合并的过程中,configmap的大小可能会超过 1M,而configmap的大小限制是 1M,超过后会生成新的configmap,挂载spec的变化导致 Prometheus Pod 重新调度
可是为什么会反复重新调度呢?
平台有巡检服务的逻辑,会定时创建新服务,每个服务都会下发自己的PrometheusRule,发布成功后,会销毁掉这个服务,PrometheusRule也会销毁,在某些场景下,到了文件分割的临界点,巡检服务的PrometheusRule的存在与否,直接导致configmap的数量+1和-1,最终导致Pod 反复重新调度
问题四:CPU 利用率震荡问题分析
涉及Rate计算逻辑、时间戳设置逻辑,参见文章:https://ryanwuer.github.io/2024/07/17/prometheus-cpu-fluctuation/
问题五:查询慢
老生常谈的高基数问题,基数可以理解为所有 Label 对可能的组合数,Prometheus的查询性能和数据的基数有关系,基数越高,写入和查询性能越差
我们用到的 CD组件:Argo-rollout(版本:v0.9.3)组件就存在这样的问题,通过指标裁剪,不再返回已经删除的argo-rollout的对应的指标
关于 label 较为合理的基数,可参考 Grafana 的两篇文章:
what-are-cardinality-spikes-and-why-do-they-matter
high-cardinality-metrics
问题六:指标拉取异常
界面报错:
分析:zone-kk、zone.kk 作为 label的键在K8s里是合法的,但是转化为指标时,会都变为zone_kk,导致出现label名不唯一的问题,如下:
template:
metadata:
labels:
zone-kk: "b"
zone.kk: "b"如果某个Target Pod出现了上述问题,Prometheus会直接丢弃该指标,导致数据不完整